
Selected Research Projects
2014
Pose Maker: A Pose Recommendation System for Person in the Landscape Photographing
In this work, we proposed pose recommendation system. Given a user-provided clothing color and gender, this system shall not only offer some suitable poses, but also assist users to take high visual quality photos by generating the visual effect of person in the landscape pictures.
2018

DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks
In this work, we propose a novel framework for instance-level image translation by Deep Attention GAN (DA-GAN). Such a design enables DA-GAN to decompose the task of translating samples from two sets into translating instances in a highly-structured latent space.
2019

Characterizing Bias in Classifiers using Generative Models
In this work, we incorporate an efficient search procedure to identify failure cases and then show how this approach can be used to identify biases in commercial facial classification systems.

Unpaired Image-to-Speech Synthesis with Multimodal Information Bottleneck
In this work, we introduce the problem of translating instances from one modality to another without paired data. Specifically, we perform image-to-speech synthesis for demonstration.
Click to play audio

Neural TTS Stylization with Adversarial and Collaborative Games
In this work, we introduce an end-to-end TTS stylization model that offers enhanced content-style disentanglement ability and controllability. Given a text and a reference audio as input, our model can generate human fidelity speech that satisfies the desired style conditions.


M3D-GAN: Multi-Modal Multi-Domain Translation with Universal Attention
We present a unified model, M3D-GAN, that can translate across a wide range of modalities (e.g., text, image, and speech) and domains (e.g., attributes in images or emotions in speech). We introduce a universal attention module that is jointly trained with the whole network and learns to encode a large range of domain information into a highly structured latent space. We use this to control synthesis in novel ways, such as producing diverse realistic pictures from a sketch or varying the emotion of synthesized speech. We evaluate our approach on extensive benchmark tasks, including imageto-image, text-to-image, image captioning, text-to-speech, speech recognition, and machine translation. Our results show state-of-the-art performance on some of the tasks.
2020

MULTI-REFERENCE NEURAL TTS STYLIZATION WITH ADVERSARIAL CYCLE CONSISTENCY
In this work, we propose an adversarial cycle consistency training scheme with paired and unpaired triplets to ensure the use of information from all style dimensions. We use this method to transfer emotion from a dataset containing four emotions to a dataset with only a single emotion.
2021

LEARNING AUDIO-VIDEO REPRESENTATIONS BY CROSS-MODAL ACTIVE CONTRASTIVE CODING
In this work, we propose CrossModal Active Contrastive Coding that builds an actively sampled dictionary with diverse and informative samples, which improves the quality of negative samples and achieves substantially improved results on tasks where incomplete representations are a major challenge.
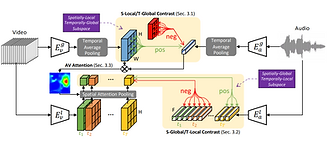
Contrastive Learning of Global-Local Video Representations
In this work, we propose to learn video representations that generalize to both the tasks which require global semantic information (e.g., classification) and the tasks that require local fine-grained spatio-temporal information (e.g., localization). We show that the two objectives mutually improve the generalizability of the learned global-local representations, significantly outperforming their disjointly learned counterparts.