
Highlight Projects
2023
Is Imitation All You Need? Generalized Decision-Making with Dual-Phase Training
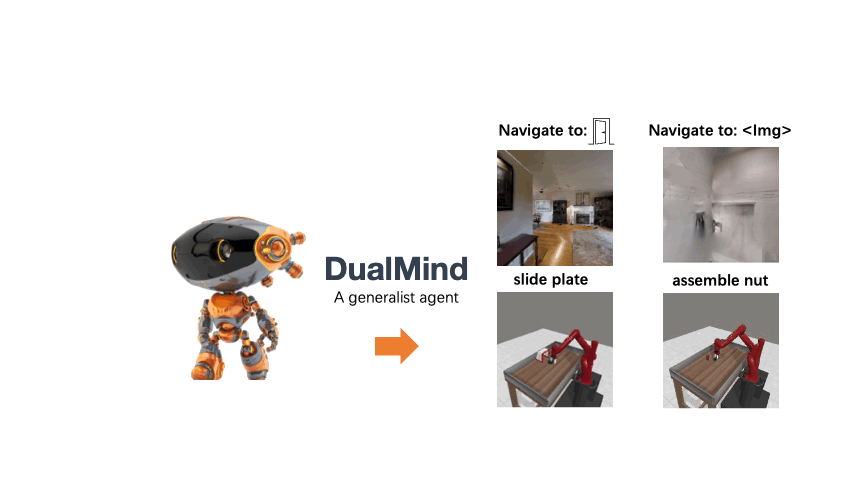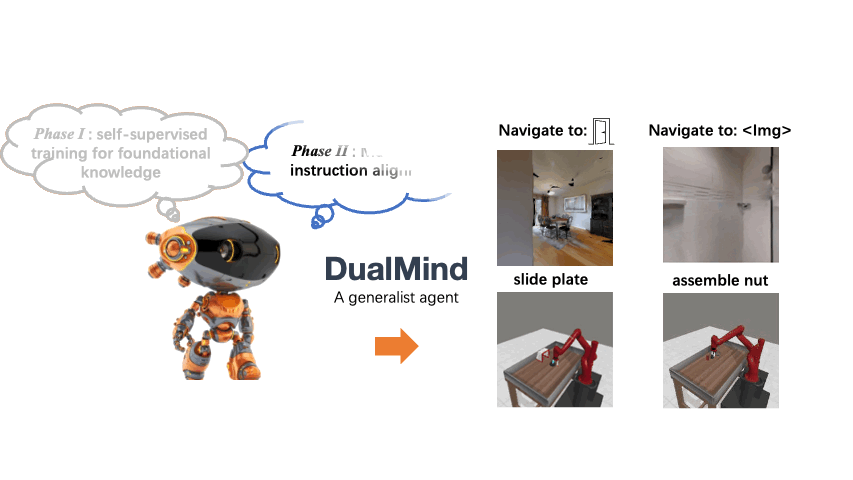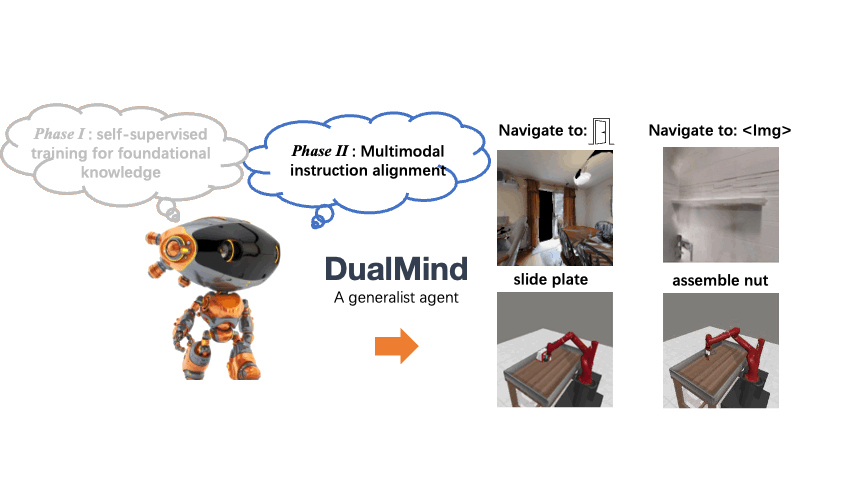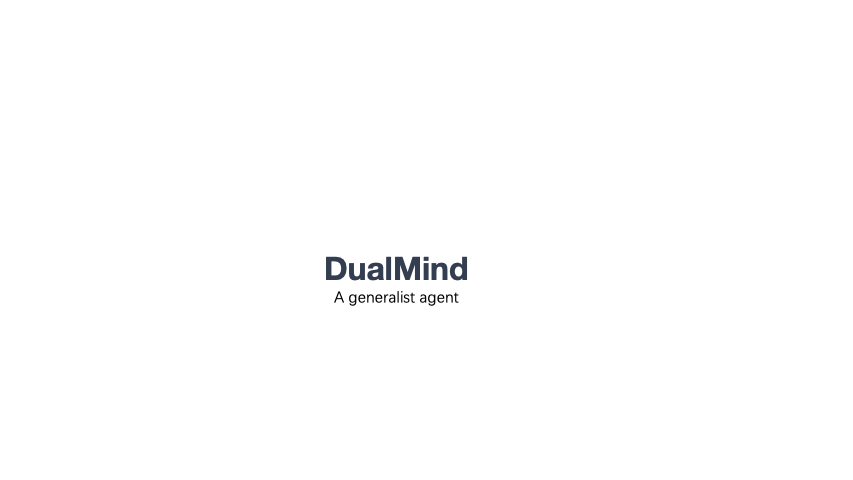
We introduce DualMind, a generalist agent designed to tackle various decision-making tasks that addresses challenges posed by current methods, such as overfitting behaviors and dependence on task-specific fine-tuning. DualMind uses a novel “Dual-phase” training strategy that emulates how humans learn to act in the world. DualMind can handle tasks across domains, scenes, and embodiments using just a single set of model weights and can execute zero-shot prompting without requiring task-specific finetuning. DualMind demonstrate its superior generalizability compared to previous techniques, outperforming other generalist agents by over 50% and 70% on Habitat and MetaWorld, respectively.
SMART: SELF-SUPERVISED MULTI-TASK PRETRAINING WITH CONTROL TRANSFORMERS

In this work, we formulate a general pretraining-finetuning pipeline for sequential decision making, under which we propose a generic pretraining framework Self-supervised Multi-task pretrAining with contRol Transformer (SMART). By systematically investigating pretraining regimes, we carefully design a Control Transformer (CT) coupled with a novel control-centric pretraining objective in a self-supervised manner.
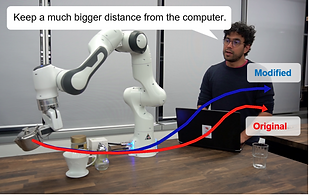
LATTE: LAnguage Trajectory TransformEr
This work proposes a flexible language-based framework that allows a user to modify generic robotic trajectories. Our method leverages pre-trained language models (BERT and CLIP) to encode the user’s intent and target objects directly from a free-form text input and scene images, fuses geometrical features generated by a transformer encoder network, and finally outputs trajectories using a transformer decoder, without the need of priors related to the task or robot information.